
 时间排序
时间排序-
 [内门弟子]吴艺强
0
[内门弟子]吴艺强
01. redis分布式(https://segmentfault.com/a/1190000007029987)
1) 安装ruby,因为需要使用redis-trib.rb文件

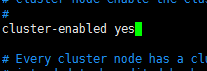
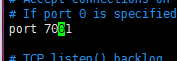
2) 复制redis bin下的文件,并修改conf中的端口和cluster-enable属性

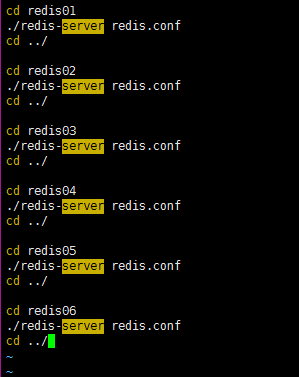
3) 启动脚本
修改权限

ps –aux|grep redis create命令可选replicas参数,replicas表示需要有几个slave,前面三个是主服务,后面三个从服务地址

启动报错,百度说明缺少ruby执行redis的相关依赖(http://blog.csdn.net/shinebar/article/details/54585050)

ruby版本不够,进行升级

(https://www.cnblogs.com/ding2016/p/7903147.html)
(http://blog.csdn.net/xiaojin21cen/article/details/70445545)
SCL(Software Collections)可以让你在同一个操作系统上安装和使用多个版本的软件,而不会影响整个系统的安装包
scl enable *****bash 启动一个会话(不懂,不过没执行就无法使用ruby -v)

启动失败

因为绑定了127.0.0.1,要么改bind,要么修改启动ip为127.0.0.1
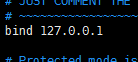
新问题

需要清除杀掉redis实例,然后删除每个节点下的临时数据文件appendonly.aof,dump.rdb,nodes-703x.conf,然后再重新启动redis实例即可启动集群。

用redis-cli 登录到每个节点执行 flushall 和 cluster reset
启动成功
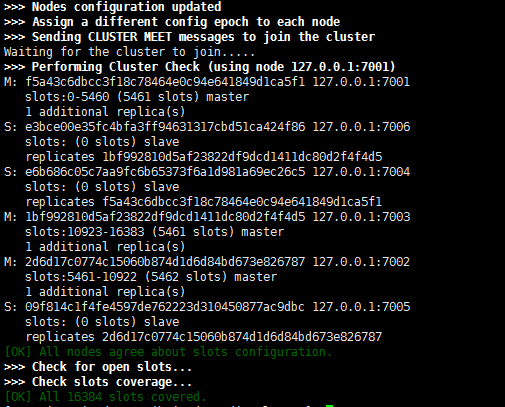
cluster nodes 查看node情况

redis-trib.rb具有以下功能:(http://blog.csdn.net/xfg0218/article/details/56505216)
1、create:创建集群
2、check:检查集群
3、info:查看集群信息
4、fix:修复集群
5、reshard:在线迁移slot
6、rebalance:平衡集群节点slot数量
7、add-node:将新节点加入集群
8、del-node:从集群中删除节点
9、set-timeout:设置集群节点间心跳连接的超时时间
10、call:在集群全部节点上执行命令
11、import:将外部redis数据导入集群

集群关闭
关闭集群需要逐个关闭
客户端连接需要加-c:客户端重定向,是因为Redis Cluster中的每个Master节点都会负责一部分的槽(slot),存取的时候都会进行键值空间计算定位key映射在哪个槽(slot)上,如果映射的槽(slot)正好是当前Master节点负责则直接存取,否则就跳转到其他Master节点负的槽(slot)中存取,这个过程对客户端是透明的。
-c标识以集群方式登录


redis集群实现算法和相关操作(https://www.cnblogs.com/hjwublog/p/5681700.html)
一些原理
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽(hash slot)的方式来分配的,一致性哈希对向集群中新增和删除实例的支持很好,但是哈希槽对向集群新增实例或者删除实例的话,需要额外的操作,需要手动的将slot重新平均的分配到新集群的实例中。
redis cluster 默认分配了 16384 个slot,当我们set一个key时,会用CRC16算法来取模得到所属的slot,然后将这个key分到哈希槽区间的节点上,具体算法就是:CRC16(key)%16384。
Redis 集群会把数据存在一个master节点,然后在这个master和其对应的salve之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的master节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的salve节点,充当master。
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。
Jedis Cluster 会自动去发现集群中的节点,所以JedisClusterNodes只需要 add一个实例

需要将连接对象从 Jedis 换成 JedisCluster
可以直接进行重定向获取,说明redis集群有效
 编辑于2018-03-25
编辑于2018-03-25
- 去第 页



